Final Report
Financial RAG System Using Intelligent Query Routing and a Vision Self-Correction Agent
Summary
This project implements an "Intelligent Routing-based Hybrid Corrective Agent" system to accurately extract textual and complex table data from PDF reports distributed through the Financial Supervisory Service's electronic disclosure system, DART. Going beyond the three methods proposed in the original assignment, the final implementation adopts a SOTA architecture that combines a neural reranker with the recent vision-based retrieval model ColPali. The system addresses retrieval-slot confusion and table structure collapse, which are limitations of simple RAG, and achieved an Exact Match of 0.8 and an LLM-as-a-judge score of 4.2, a large improvement over the basic RAG EM of 0.6. It also verified the usefulness of a dynamic extension logic in which the agent uses self-correction to handle cases where the data required by a question continues onto the next page.
Keywords Agentic RAG, Multimodal LLM, Intelligent Routing, Hybrid Retrieval
1. Introduction
Business reports, which are key indicators for judging corporate financial soundness and management performance, consist of hundreds of pages of semi-structured and unstructured data. However, conventional simple RAG systems have two serious weaknesses. First, retrieval slots are often contaminated by the semantic homogeneity of financial terms such as "consolidated cash flow" and "short-term borrowings," which are shared by many companies. This causes documents from the wrong company to enter the retrieval set. Second, complex table structures can be broken during chunking, causing hallucination.
To solve these problems, this project adopts Gemini 3.1 Flash Lite, which has high-resolution visual reasoning ability, as the core engine. The goal is to complete an "intelligent loop" that precisely understands the intent of the user's question, filters only relevant data, and uses a vision agent to search for omitted information in real time. The final output goes beyond simple information retrieval and supports a financial intelligence agent that guarantees the reliability of top-ranked evidence through neural reranking.
This technology has high practical value across the financial industry. It can reduce the time required by analysts at asset management companies or securities firms to manually investigate disclosure materials, while accurately capturing subtle numerical changes that humans may miss. It can also help companies quickly understand related information, improve the objectivity of decision-making, and minimize operational risk.
2. Task Formulation
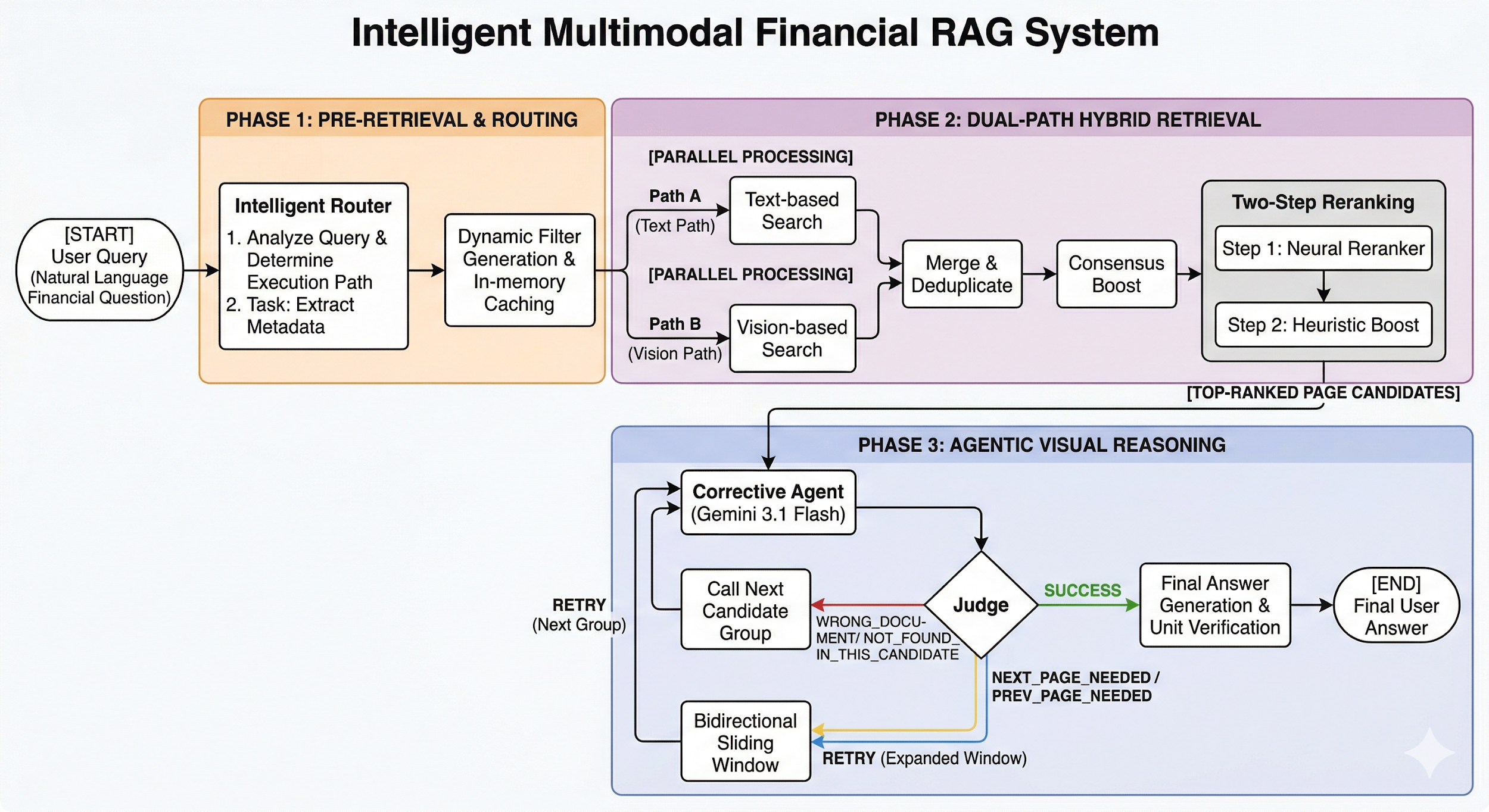
2.1. Overall System Structure: Four-stage Agentic Pipeline
This project extends the three-stage structure from the proposed system into a more advanced four-stage pipeline by adding a neural reranking stage to guarantee the reliability of retrieval results.
- Step 0 (Intelligent Query Router): extracts the target company from the question and fixes the retrieval scope at runtime to prevent false matches.
- Step 1 (Dual-Path Retrieval): Path A (Text) captures textual context by combining BM25 and vector search. Path B (Vision) improves speed and accuracy for visual-feature retrieval by upgrading from simple image rendering to ColPali vision-language indexing.
- Step 1.5 (Neural Reranking): uses BAAI/bge-reranker-v2-m3 to reorder the retrieved candidates and select the top K pages most relevant to the question.
- Step 2 (Agentic Visual Reasoning): Gemini analyzes selected page images, verifies whether the document is correct, and dynamically calls following pages within
MAX_EXPANSIONwhen a table is cut off.
2.2. Agent Judgment and Self-Correction Logic
The agent does not simply generate an answer; it performs the following autonomous judgments.
- NOT_FOUND_IN_THIS_CANDIDATE: immediately discards a candidate when the desired item is not on the retrieved page or when the data belongs to a different company.
- NEXT_PAGE_NEEDED: autonomously expands the search range when a table or context is cut off at the bottom of the page. This was especially important for complex data such as "R&D expenses" or footnote sections spanning multiple pages.
- Stopping Criteria: to prevent infinite loops or excessive token usage, the maximum number of expansion pages is set to
MAX_EXPANSION = 3. If no answer is found before the threshold is reached, the agent transitions toNOT_FOUND_IN_THIS_CANDIDATEand terminates the loop.
2.3. Evaluation Method and Ablation Study
To objectively validate the project, the following evaluation framework was built.
- Metrics: Exact Match (EM), which measures whether the numerical answer exactly matches the gold value, is the main metric. ROUGE-L, BLEU, and LLM-as-a-judge satisfaction scores from 1 to 5 are also used to assess qualitative answer quality.
- Quantitative Evaluation: performance changes are measured against a baseline (Method 0). Ablation studies quantify the contribution of Intelligent Routing, Neural Reranker, and the Vision Agent's Sliding Window by removing each module and measuring the performance drop.
- Qualitative Evaluation: case studies analyze why the agent chose to expand a specific page or perform filtering, and failure cases are collected to identify edge-case causes.
3. Dataset
3.1 Dataset Source and Composition
- Source: regular disclosure PDF reports from Korean listed companies collected through DART.
- Data scale: unstructured data averaging 300 to 600 pages per company.
- Characteristics: large tables such as balance sheets and income statements, plus hundreds of pages of explanatory footnotes.
3.2 Preprocessing and Usage
- Metadata Injection (Text): when splitting text with PyMuPDFLoader, metadata such as document filename and page number is forcibly inserted at the beginning of each chunk to prevent context loss during vectorization.
- High-Res Rendering (Vision): PyMuPDF (fitz) dynamically renders target pages for agent verification as lossless high-resolution Base64 images at a 2.0 matrix scale.
- Dynamic Pool Update: an extensible pipeline automatically updates the routing target company pool at runtime based on PDF filename rules in a specific folder.
3.2. Database Architecture and System Integration
The system is designed as a dual-path architecture so that text retrieval and visual retrieval complement each other. Text handles semantic context, while vision preserves information that can be lost during PDF text extraction.
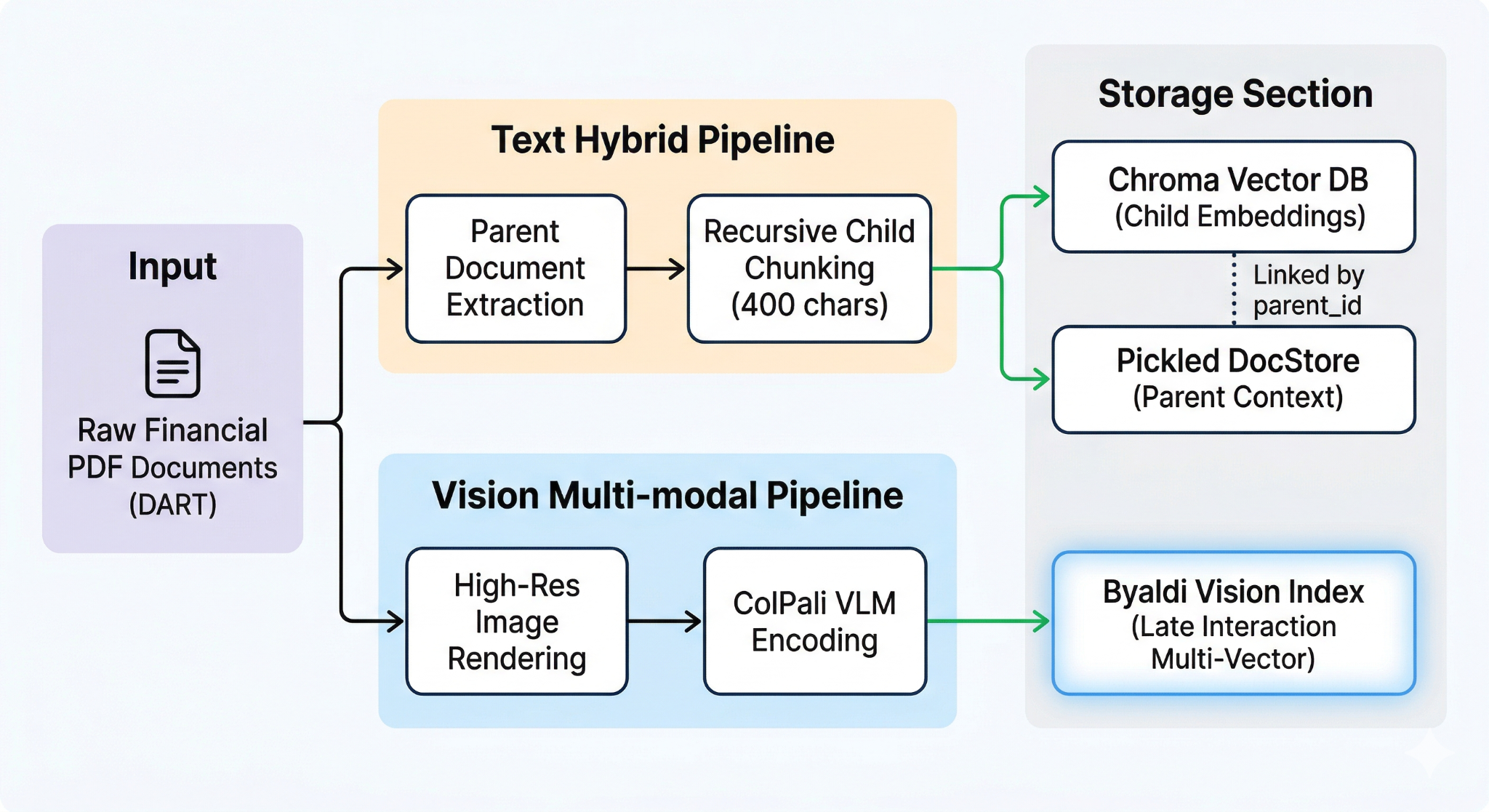
Text Hybrid Path
- Parent-Child structure: documents are split into small child chunks of around 400 characters to increase retrieval sensitivity, but when retrieval succeeds, the full parent page containing the actual context is passed to the agent. This solves the context-fragmentation problem of simple RAG at the architectural level.
- Ensemble Retrieval: BM25 keyword search and semantic search are fused at a 5:5 ratio to capture both quantitative keywords and qualitative context.
Vision Multi-modal Path
- ColPali-based Late Interaction: each PDF page is indexed as a high-resolution image vector. Visual layout information such as table grids, font emphasis, and merged cells, which is often lost during text extraction, is preserved and provided as evidence for the vision agent.
System Integration
- Runtime MetaData Filtering: based on the company name extracted by the Intelligent Router, dynamic filtering tracks only the source tag of the relevant company at retrieval time. This blocks interference from other companies' data even inside a database with tens of thousands of pages.
4. Model Selection
4.1. Model Selection
To secure both accuracy and response speed, the optimal technology stack was selected for each module.
- Main model: Gemini 3.1 Flash Lite
Reason: because the system must perform an agentic loop, low latency and cost efficiency are essential. Its strong native multimodality, which directly understands table structures inside images without separate OCR, makes it suitable as the Vision Agent controller. - Text Embedding model: jhgan/ko-sroberta-multitask
Reason: this SBERT-based model is specialized for measuring semantic similarity between Korean sentences and provides stable retrieval performance for Korean financial Q&A. Its light model size minimizes indexing and retrieval overhead. - Neural Reranker model: BAAI/bge-reranker-v2-m3
Reason: financial reports often share duplicate section titles such as "consolidated statements of financial position" and "operating profit," causing semantic homogeneity during initial bi-encoder retrieval. A cross-encoder BGE reranker directly compares the question and document, greatly improving top-K fit. - Vision Retrieval: ColPali
Reason: traditional text extraction pipelines lose PDF visual structure such as table layouts. ColPali applies late interaction to a vision-language model and indexes visual features directly from images, complementing text-based retrieval while preserving table lines and layout.
4.2. Experiment and Analysis Method
To verify the contribution of each module, a baseline, intermediate experimental groups, ablation groups, and the full proposed system were compared.
- Method 0 (Baseline): the most basic text-based hybrid RAG model.
- Method 1 (Vision Only): an experimental group that generates answers only from ColPali image retrieval results without text information.
- Method 2 (Dual Basic): simply combines text and vision retrieval results and generates a one-shot answer without an agent loop or self-feedback.
- w/o Filter (Ablation): removes company-name pre-filtering through Intelligent Query Router from the SOTA model to measure noise from other company documents.
- w/o Reranker (Ablation): removes the Neural Reranker from the SOTA model and measures accuracy when the agent loop uses only initial keyword/embedding retrieval results.
- w/o Agent Window (Ablation): removes the Sliding Window page-expansion function to test whether complex table data can be processed from a single page.
- SOTA (Full Proposed): the final integrated model combining pre-filtering, neural reranking, agentic vision feedback, and window expansion.
This setup makes it possible to evaluate not only final performance but also the practical value and cost of each architectural choice.
5. Experimental Environment and Results
5.1. Experimental Setup
The experiment was conducted in an environment configured for local PDF rendering, vector retrieval, vision retrieval, neural reranking, and Gemini-based agent reasoning.
Golden Set: to prove the effectiveness of this project, ten difficult financial questions that cannot be solved by simple search alone were manually selected from DART disclosure documents.
Evaluation metrics:
- Exact Match (EM): the strictest metric, measuring whether the number and unit exactly match the gold answer.
- LLM-as-a-judge: Gemini 1.5 Pro evaluates not only the answer value, but also contextual consistency and source citation accuracy on a 1-to-5 scale.
- Latency & Token Usage: measures operational cost and real-time usability under agentic loops.
5.2. Experimental Results: Metrics and Model Comparison
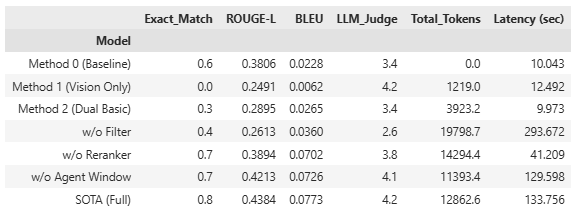
The results show that the SOTA model achieved the best performance with an Exact Match of 0.8, compared with 0.6 for the text-based baseline.
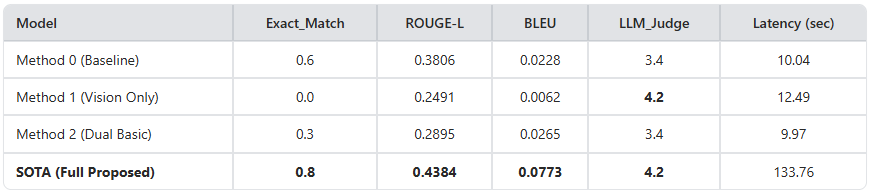
Although the Vision Only model failed at mechanical matching, it recorded a high LLM-judged score of 4.2, demonstrating the strong potential of extracting information from images. However, the large increase in latency, about 13 times higher, was observed as the cost of the SOTA model's sequential agentic loop and neural reranking process. In a financial domain where integrity and accuracy matter far more than processing speed, this is a reasonable tradeoff.
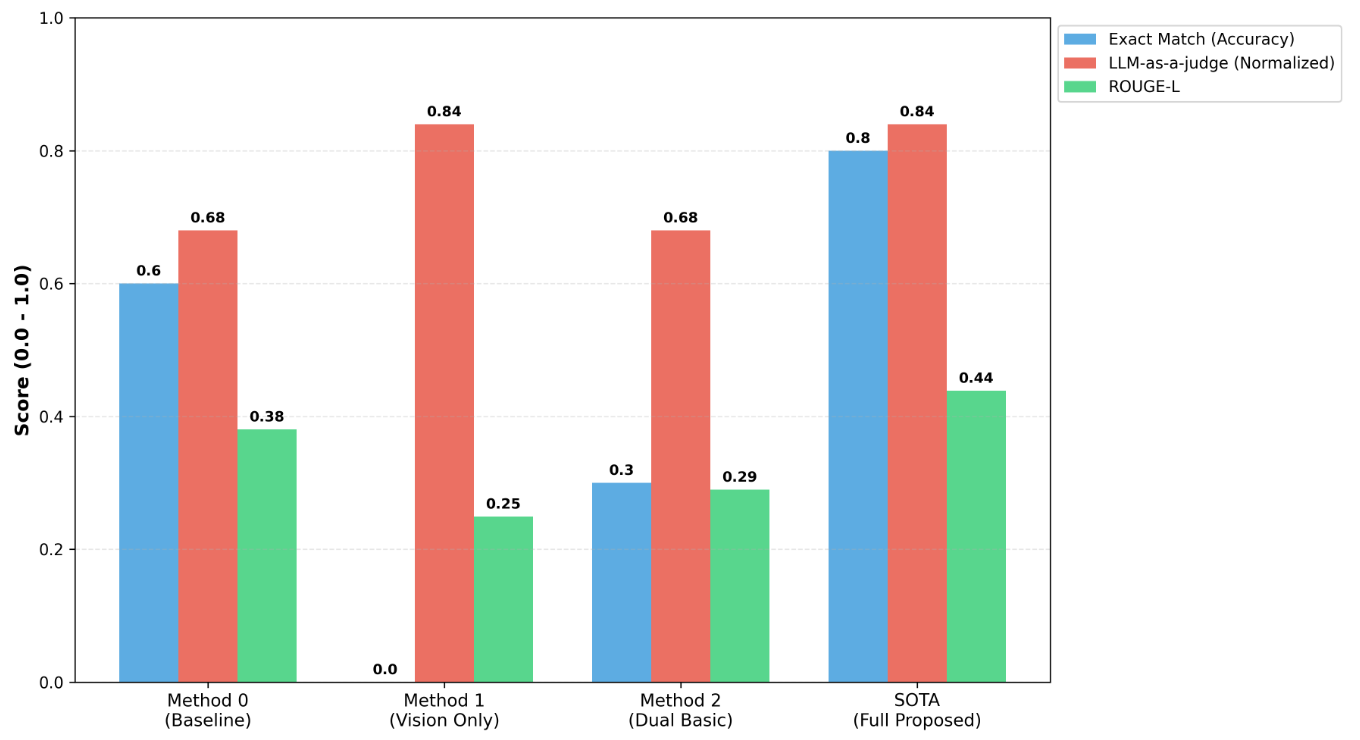
5.3. Quantitative Analysis: Ablation Study
Ablation results show that all three key modules contribute to final accuracy: intelligent routing, neural reranking, and sliding-window page expansion.
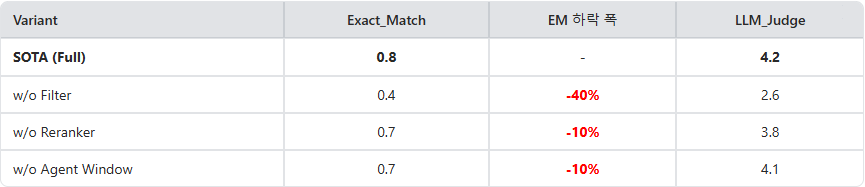
Role analysis by module:
- Intelligent Routing: the 40% accuracy drop after removing filtering is caused by semantic homogeneity in financial documents. Many corporate reports share identical section titles, so without fixing the company name in advance, vector search exposes similar pages from other companies. Intelligent Routing blocks this entity hallucination by limiting the search space to the target company.
- Neural Reranking: neural scores based on cross-attention compensate for subtle context missed by bi-encoder retrieval and produced an additional 10% performance gain. It guarantees the quality of the top-K candidates by comparing the specific value requested by the question, such as distinctions between current and prior period, with document content.
- Sliding Window: financial statements often suffer from truncation when tables continue across page boundaries or footnotes extend onto the next page. The 10% performance drop without page expansion proves that the agent's ability to explore surrounding context and reconstruct information is essential for complex table analysis.
5.4. Qualitative Analysis: Case Study
The system's effectiveness was analyzed using generated answers and agent reasoning logs.
Case 1 (Sliding Window): when a key table continued onto the next page, the agent recognized that the current candidate was incomplete, requested an additional page, and recovered the missing context.

Case 2 (Hallucination Prevention through Intelligent Routing): when two companies with similar names, Samsung SDI and Samsung Electronics, appeared in retrieval candidates, the router fixed the search scope to the explicitly requested Samsung Electronics and prevented the critical error of answering with another company's financial numbers.

6. Use of Generative Models
Gemini was used not only as an answer generator but also as the controller of the entire agentic workflow.
6.1. Use Inside the System Architecture
Gemini 3.1 Flash Lite was used as an Agent Controller for the entire pipeline rather than a simple text generator.
- Intelligent Query Routing (Zero-shot): analyzes the user's natural-language intent and extracts the target entity and specific section. A constraint such as "answer with only one word without complex explanation" standardizes the data passed to the next pipeline stage.
- Vision Verification (Role-playing): when analyzing page images, the agent is assigned the role of a financial document auditor. It does not merely read numbers, but double-checks whether table period and unit information match the question.
- Self-Correction Logic (State Machine): agent responses are output as a JSON schema with five explicit statuses, such as SUCCESS, NEXT_PAGE_NEEDED, and WRONG_DOCUMENT, enabling a state-machine-based agentic loop in which the LLM controls pipeline flow.
- Final Synthesis (Evidence-based): when generating final output from verified evidence pages, document name and page number must be specified to preserve knowledge transparency.
6.2. Development and Documentation Assistance
Outside the system itself, AI was used as an auxiliary tool to improve development productivity.
- Agent logic implementation assistance: helped write exception-handling logic for complex agentic loops and regular-expression-based data parsing code.
- Modular and extensible architecture design: helped modularize Retrieval, Reranker, and Agent Loop so they can operate independently while connecting flexibly, making feature changes and new-data additions easier to maintain.
- Report writing and visualization: helped plan the logical structure of this final report and generate images for visualizing performance-analysis results.
7. Conclusion and Future Work
This project confirmed that combining intelligent routing, neural reranking, vision retrieval, and agentic self-correction can improve reliability in financial PDF question answering. It also showed that multimodal retrieval is especially useful for tables and disclosure reports where layout matters.
- Latency Reduction: the current latency of about 133 seconds needs improvement for user experience. Retrieval and reasoning will be converted to asynchronous parallel processing, and token optimization plus KV caching will be applied for frequent agent-loop calls.
- Tool-Augmented Reasoning: beyond numerical extraction, the agent will be given tools for unstructured-data analysis so that it can calculate year-over-year growth rates or financial ratios autonomously.
- Difficulty of Multi-Document Cross-Referencing: the current system specializes in precise analysis of a single company's report, so complex questions comparing values across multiple large documents, such as competitor comparisons, may still cause information confusion.
References
- Google Cloud, "Gemini 3.1 Flash Lite Technical Documentation".
- BAAI, "BGE Reranker v2: Multi-stage Retrieval for Production".
- LangChain, "Agentic RAG: Corrective Strategies for Financial Analysis".
- Faysse, et al. "ColPali: Efficient Document Retrieval with Vision Language Models", 2024.
- Cuconasu, et al. "The Power of Prompting: Engineering RAG Systems for Real-World Applications", 2024.
- Zhang, et al. "Agentic Retrieval-Augmented Generation for Complex Question Answering", 2024.
- Nelson F. Liu, et al. "Lost in the Middle: How Language Models Use Long Contexts", 2023.