Project Report
Diffusion Model Style Adaptation Using Customizing LoRA
Summary
This project builds a complete pipeline for adapting Stable Diffusion to a custom visual style with LoRA. Three datasets were prepared: web-crawled images, generated images, and real photographs. Each dataset was captioned, converted into the Hugging Face imagefolder format, trained with LoRA, and evaluated through before/after generation and ablation studies on rank and alpha.
Keywords LoRA, Diffusion Model, Stable Diffusion, Fine-tuning
1. Introduction
Recent generative AI systems can create high-quality images from text prompts, and diffusion models such as Stable Diffusion are widely used as representative text-to-image models. However, a base diffusion model has limited ability to reflect a user's desired visual style or domain without additional adaptation.
Full fine-tuning of a diffusion model requires a large amount of computation and storage because all model parameters must be updated. LoRA reduces this burden by adding small low-rank matrices to specific layers and training only those additional parameters. This makes it possible to customize model behavior even in a limited experimental environment.
This project applies LoRA to Stable Diffusion v1.5 and compares whether different custom datasets can transfer their visual characteristics to the generated images. The work also studies how LoRA rank and alpha affect the degree of style reflection and generation quality.
2. Task Formulation
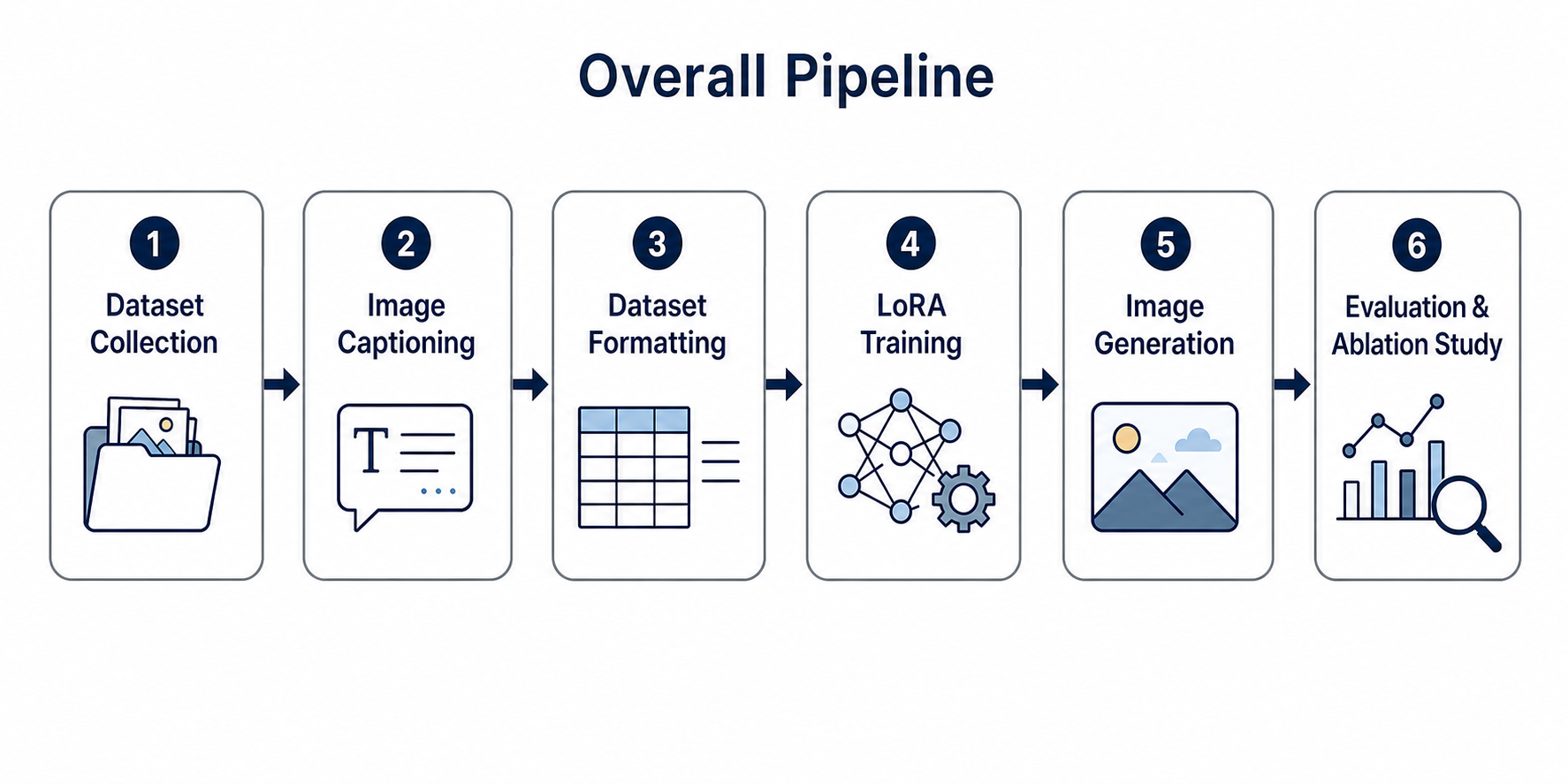
2.1 Overall Pipeline Structure
- Dataset Collection: builds custom datasets from web-crawled images, generated images, and real photographs.
- Image Captioning: uses a BLIP-based captioning model to automatically create text descriptions for each image and organize them as caption metadata.
- Dataset Formatting: organizes images and captions in the Hugging Face
imagefolderformat and buildsmetadata.csv. - LoRA Training: applies LoRA adapters to the UNet attention layers of Stable Diffusion v1.5 to learn visual characteristics for each dataset.
- Image Generation: applies trained LoRA weights to the base Stable Diffusion pipeline and generates prompt-based images.
- Evaluation & Ablation Study: compares results before and after LoRA and analyzes generated outputs and style reflection under changes in rank and alpha.
2.2 Dataset Construction Method
The dataset was intentionally divided into three types so that the difference between artificial styles and real-photo styles could be examined. This design allows the experiment to compare whether LoRA mainly learns texture, color, object structure, or photographic lighting depending on the dataset source.
- Dataset A - Web Crawled Images: pixel-art style images collected from the web, used to check how much web-image-based style characteristics can be reflected.
- Dataset B - Generated Images: images intended to have a paper-craft or paper-cutout style, including houses, flower gardens, animals, and landscapes.
- Dataset C - Real Images: real images containing snowy streets, buildings, outdoor landscapes, texture, and lighting conditions.
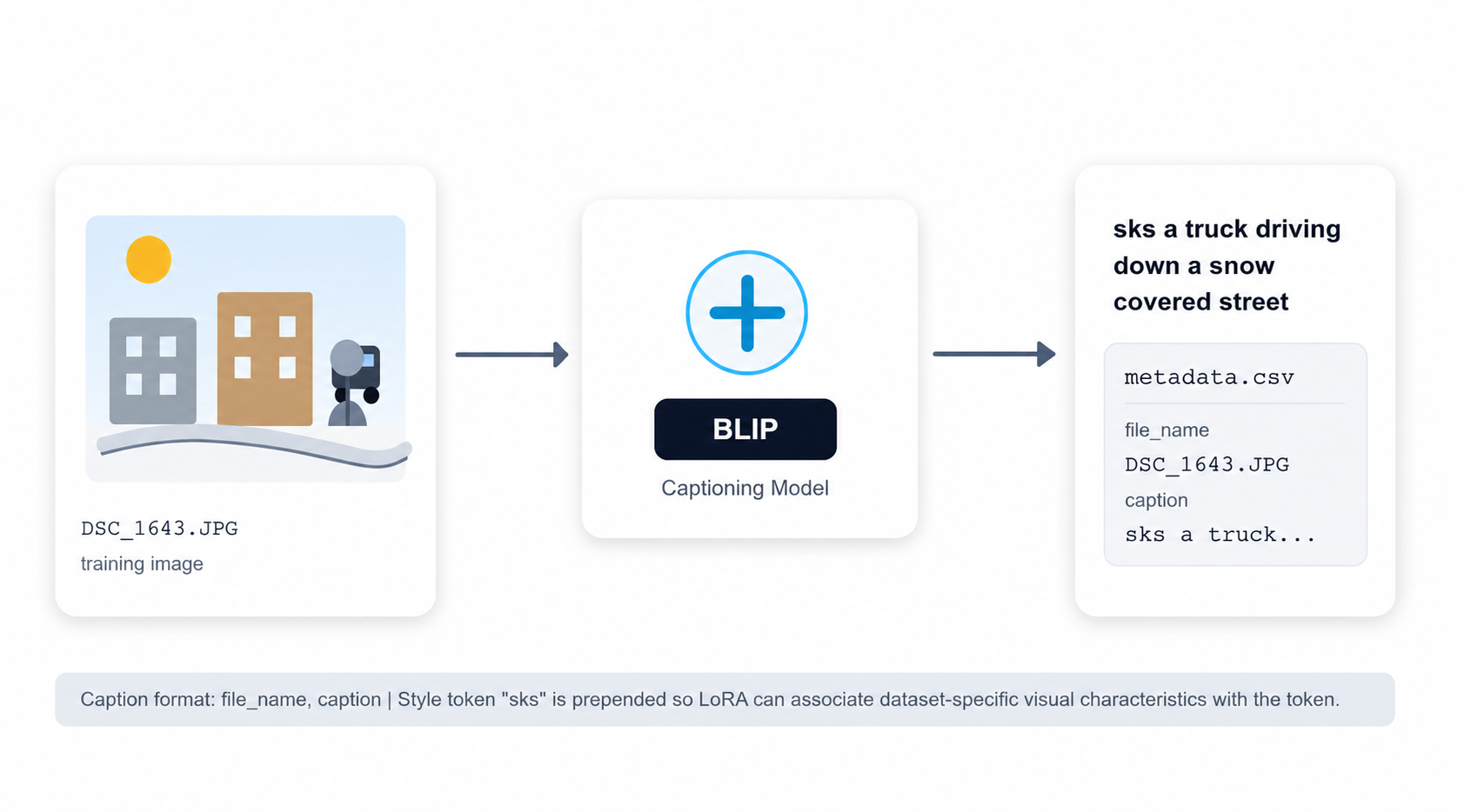
2.3 Captioning and Metadata Construction
Each image was paired with a text caption so the model could associate visual features with language conditions during training. BLIP was used to generate captions automatically, and the results were checked and organized into metadata.
3. Dataset
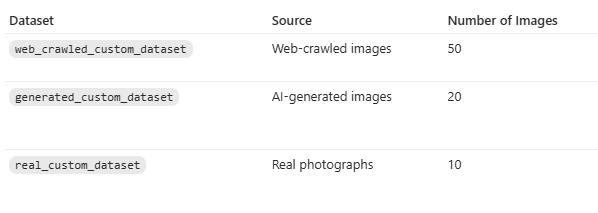
3.1 Dataset Composition
The dataset was designed to compare three style adaptation scenarios: web-collected stylized images, generated stylized images, and real-world photographs. The number of samples and content type differ by dataset, but all were converted into the same training format for fair comparison.
3.2 Data Preprocessing
Images were collected, resized, and organized into folders by dataset.
Captions were stored in metadata.csv so that the Hugging Face
imagefolder loader could read image-caption pairs. This
preprocessing step makes the training notebooks reusable across different
datasets.
Since LoRA training is sensitive to dataset quality, duplicated, low-quality, or style-inconsistent images were removed as much as possible. The metadata format also made it easier to inspect whether each caption described the image content with enough detail.
3.3 Data Visualization
Dataset samples were visualized before training to verify whether each dataset contained the intended visual distribution. This step was important because style adaptation quality depends strongly on the consistency of the training images.

4. Model Selection
4.1 Stable Diffusion
Stable Diffusion is a latent diffusion model that performs denoising in latent space instead of pixel space. This reduces computation while still producing high-resolution images. The model consists of a text encoder, UNet denoiser, and VAE decoder, and the UNet attention layers are a natural target for LoRA adaptation.
Stable Diffusion v1.5 was selected because it is widely supported by open-source tooling and has a stable implementation in Diffusers. This made it suitable for comparing different LoRA training conditions.
4.2 LoRA (Low-Rank Adaptation)
LoRA assumes that the parameter updates needed for adaptation can be represented in a low-rank form. Instead of updating the original weight matrix directly, LoRA trains small matrices that are added to the model's existing layers. This greatly reduces the number of trainable parameters.
In this project, LoRA adapters were applied to the attention layers of the Stable Diffusion UNet. Rank determines the size of the representation space the adapter can learn, while alpha controls the strength of the adapter's influence on the base model.
4.3 Hugging Face Diffusers & PEFT
Diffusers was used to construct the Stable Diffusion training and inference pipeline, while PEFT was used to manage parameter-efficient fine-tuning. These libraries made it possible to train, save, load, and compare LoRA adapters in a consistent workflow.
5. Experimental Environment and Results
5.1 Experimental Environment
Training and inference were performed in a notebook-based environment. The experimental settings included the Stable Diffusion checkpoint, LoRA rank and alpha values, learning rate, training steps, and prompts for before/after comparison.
5.2 Before/After LoRA Comparison
The before/after comparison checks whether the LoRA adapter changes the visual output in the intended direction while preserving prompt controllability.

For the Web Crawled dataset, after applying LoRA, the building exterior texture and color became closer to the training images. The result shows that the adapter learned the coarse texture and stylized appearance of the collected images.

For the Generated dataset, the training data intended a paper-craft or paper-cutout style. After applying LoRA, paper-like edges, layered shapes, and a more handcrafted visual impression appeared more clearly.

For the Real dataset, after applying LoRA, brown and reddish building exterior tones and realistic snowy street textures became stronger than before. However, real-image adaptation was more subtle than stylized dataset adaptation because the target style was less explicit.
Overall, LoRA did not simply copy training images; it adjusted the base model's output distribution toward the visual tendencies of each dataset.
5.3 Ablation Study
Ablation experiments were conducted to examine how rank and alpha affect the expressive capacity and strength of LoRA adaptation.
5.3.1 Rank Ablation
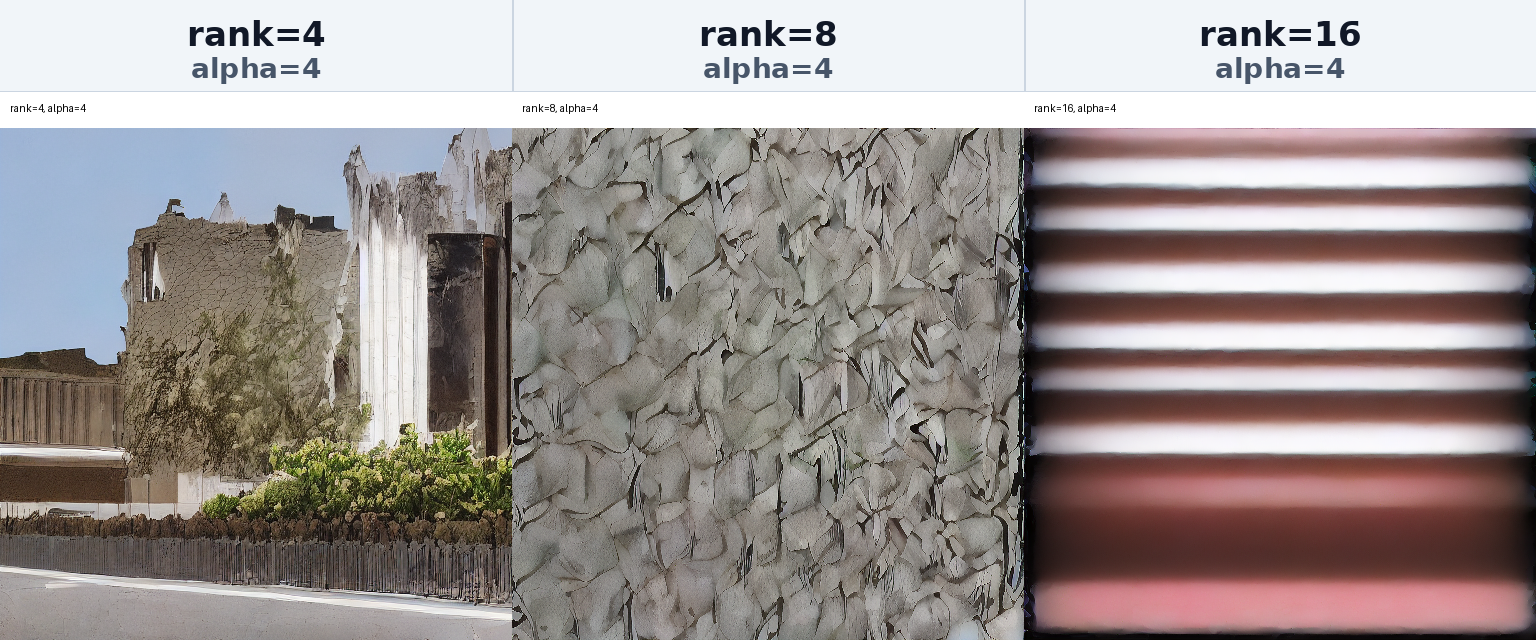
Rank determines the size of the representation space the LoRA adapter can learn. In the experiment, rank=4 reflected building shape and exterior texture relatively stably, while larger ranks could express more detail but also increased the risk of overfitting to dataset-specific artifacts.
5.3.2 Alpha Ablation
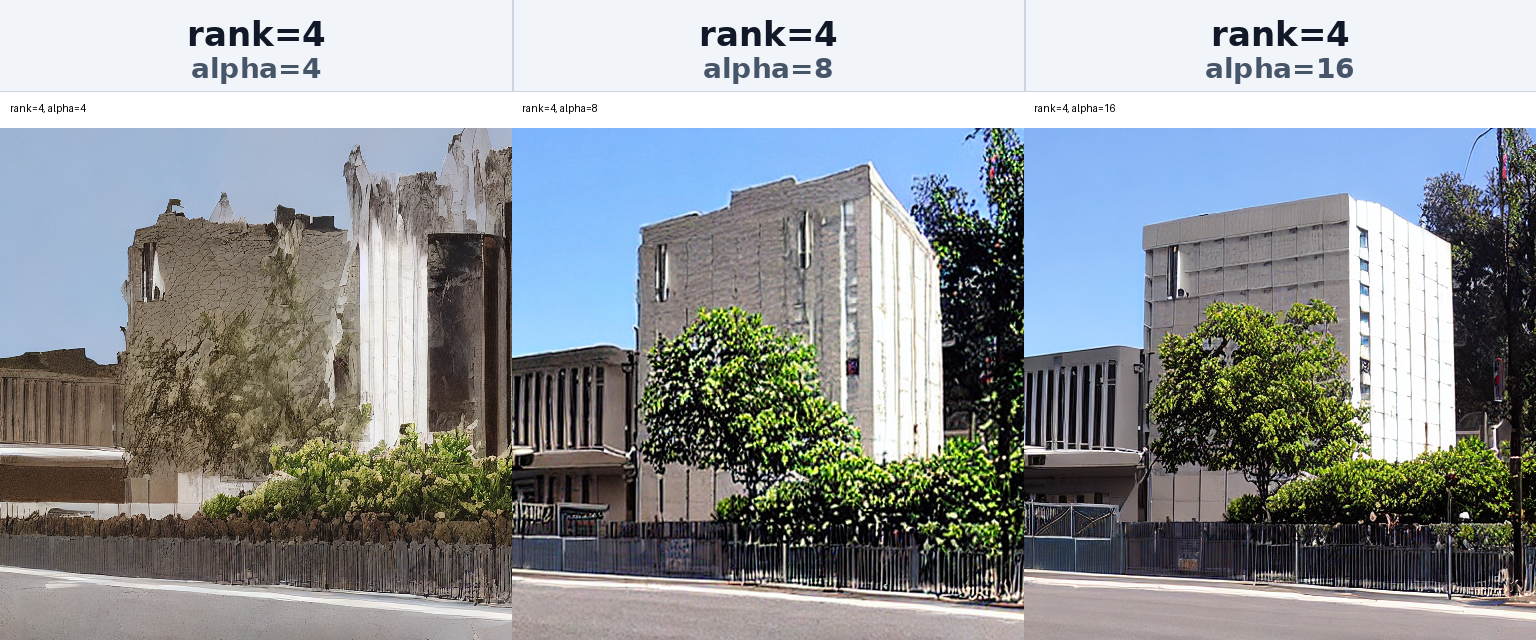
Alpha controls how strongly LoRA affects the base model output. With alpha=4, the training data texture was reflected relatively weakly, while larger alpha values produced stronger style transfer. However, if alpha becomes too large, the result can lose prompt fidelity or become visually unstable.
These results show that LoRA customization requires balancing style strength and generation stability rather than simply maximizing adapter capacity.
6. Paper Summary
6.1 LoRA: Low-Rank Adaptation of Large Language Models
The LoRA paper proposes a parameter-efficient fine-tuning method that freezes pretrained model weights and trains only low-rank decomposition matrices. Although the original paper focuses on language models, the same idea can be applied to diffusion model attention layers.
The key idea is that the update matrix needed for adaptation has a low intrinsic rank. This allows efficient training and storage while preserving most of the base model's capability.
6.2 Denoising Diffusion Probabilistic Models
DDPM formulates generation as the reverse process of gradually removing noise from a sample. During training, noise is added to data step by step, and the model learns to predict and remove that noise.
Stable Diffusion builds on this diffusion principle but performs the process in latent space. This project uses that structure as the base model and applies LoRA to adapt its visual behavior.
7. Conclusion and Future Work
This project confirmed that LoRA can efficiently adapt Stable Diffusion to custom visual datasets without full fine-tuning. The before/after comparisons show that LoRA reflects dataset-specific texture, color, and stylistic characteristics in generated images.
The experiments also showed that dataset consistency matters greatly. Styles with clear visual rules, such as paper craft, were reflected more visibly than broad real-photo datasets. This means dataset construction is as important as model tuning in style adaptation.
Future work includes expanding the dataset, improving caption quality, performing quantitative evaluation with CLIP-based metrics, and testing more detailed combinations of rank, alpha, learning rate, and training steps.
8. Project File Structure
Project root: Customizing-LoRA-for-Diffusion-Models
- 00_Customizing_LoRA.ipynb: base notebook for checking the full experimental pipeline.
- 01_dataset_training.ipynb: LoRA training by dataset and before/after comparison image generation.
- 02_ablation_rank.ipynb: ablation experiment under rank changes.
- 02_ablation_alpha.ipynb: ablation experiment under alpha changes.
- 03_test.ipynb: prompt-based generation test after loading trained LoRA/checkpoints.
- 04_monitor.ipynb: monitoring of training progress, logs, and intermediate results.
- experiment_utils.py: shared utilities for preprocessing, training loops, inference, and comparison image generation.
- environment.yml: reproducible experiment environment definition.
- data/: training datasets for web-crawled images, generated images, and real photographs.
- lora_experiments/: directory for dataset-specific training outputs, comparison images, and ablation results.
References
- Ho et al., "Denoising Diffusion Probabilistic Models", NeurIPS, 2020.
- Rombach et al., "High-Resolution Image Synthesis with Latent Diffusion Models", CVPR, 2022.
- Hu et al., "LoRA: Low-Rank Adaptation of Large Language Models", ICLR, 2022.
- Li et al., "BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation", 2022.